脳の部位を模倣した記憶構造、時間経過による減衰、感情による重み付け、睡眠による記憶整理、AIエージェントの行動の「なぜ」を検索できるメタメモリ。複合的記憶を任意のLLMで共有できるメモリレイヤーを開発
AIコネクティブカンパニーであるコーレ株式会社(本社:東京都新宿区、代表取締役:奥脇真人、以下コーレ)は、AIエージェントに"生きた記憶"データベースを与えるため、脳の構造を実装したメモリレイヤー「Cerememory(セレメモリ)」を公開しました。OSSで誰でも利用可能です。
公式サイト: https://co-r-e.github.io/cerememory-docs/ja
GitHub: https://github.com/co-r-e/cerememory

■ なぜ人間の記憶システムを参照するのか
いま、「AIエージェントに長期的な記憶を持たせる」という課題には、世界中の開発者が向き合っています。各社のメモリ機能、ベクトルDBを使ったRAG、コンテキストエンジニアリングの様々な手法。すでに多くの優れた実装が世に出ています。
ただ、それらの取り組みを俯瞰したとき、ひとつの問いに行き着きました。「AIの記憶のあり方を考えるとき、どの着地が理想になるのだろうか?」
この問いに対する答えは、実はすぐ近くにありました。私たち人間のような、生きている記憶システムです。
人間の記憶は、単に情報を保存して取り出す仕組みではありません。重要な体験は鮮明に残り、些細な出来事は薄れていく。似た記憶は混ざり合い、ひとつ思い出すと関連する記憶が連鎖的によみがえる。懐かしい香りによって、子どものころの記憶が蘇る経験は誰でもあるはずです。
眠っている間に一日の出来事が整理され、長期的な知識へと統合される。何十万年もの進化のなかで磨き上げられてきた、極めて高度な情報処理システムといえます。
Cerememoryが向き合っている問いは、「どうやってAIに記憶を持たせるか」ではなく、「人類が長い時間をかけて獲得してきた優れた記憶のしくみを、どこまでAIの記憶層に持ち込めるか」です。神経科学研究で観察される現象を、データ構造としてではなく実行系として実装する。これがCerememoryのアプローチです。
■ Cerememoryの3つの設計原則
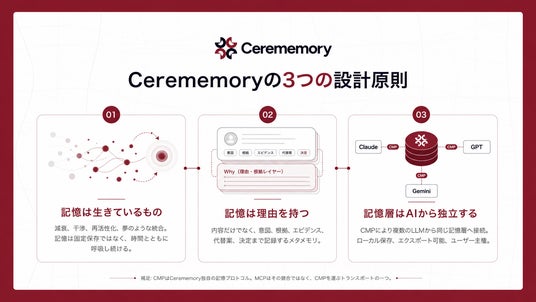
記憶は「静的に保存するもの」ではなく「動的に生きているもの」として扱う
人間の記憶は、ハードディスクのように静的に保存されているわけではありません。重要なものは強化され、使われないものは薄れ、思い出すたびに少しずつ姿を変えます。Cerememoryもこの性質を引き継ぎ、減衰、干渉、再活性化、睡眠中の夢をみているときに記憶が整理されるような動き、統合といった動的プロセスを、データ構造としてではなく実行系として実装しています。記憶は書き込んだ瞬間に固定されるのではなく、時間とともに動的に動き続けます。記憶は「内容」だけでなく「理由」を持つべきである
AIエージェントの行動の意図がわからずに困った経験をした方は多いのではないでしょうか。人が何かを覚えているとき、その記憶には「なぜそれを大事だと思ったか」「どういう判断でそうしたか」というメタ的な文脈が伴います。Cerememoryは、AIエージェントのすべての記憶レコードに「なぜそれが存在するのか」を構造化して記録するメタメモリプレーンを持たせています。意図、根拠、エビデンス、代替案、決定。AIエージェントの行動内容だけではなく理由でも記憶を辿れます。記憶層はAIから独立したレイヤーにする
人の記憶は、その人自身に属するものであり、特定の対話相手に従属するものではありません。Cerememoryも同じ立場をとります。独自プロトコル「CMP※」を通じて、Claude、GPT、Geminiなど、どのLLMからでも同じ記憶層にアクセスできます。データはローカルに保存され、いつでもエクスポート可能。AIを乗り換えても、サービスを解約しても、記憶はユーザー自身のもとに残り続けます。記憶層は、特定のAIやベンダーに所有されるべきものではありません。※補足:CMPとMCPは別のプロトコルです。名前が似ているため混同されがちですが、CMP(Cerememory Protocol)はCerememoryが記憶の読み書きのために独自に定義したプロトコル、MCP(Model Context Protocol)はAnthropicが提唱したLLMと外部ツールをつなぐためのオープン仕様です。両者は競合するものではなく、Cerememoryでは「MCPがCMPを運ぶ」関係になっています。Claude CodeやCursorなどのMCPクライアントが、CMPメッセージを内側に乗せてCerememoryエンジンに届ける、という構図です。
■ 脳の構造をそのまま設計に持ち込んだ「5ストアアーキテクチャ」
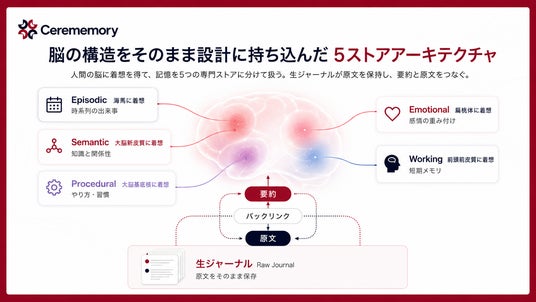
人間の脳は、記憶の種類ごとに別々の領域で処理しています。Cerememoryもこれに倣い、記憶を5つの専門ストアに分けて格納します。

これら5ストアに加えて、原文の会話・ツール出力・スクラッチパッドをそのまま保存する「生ジャーナル(Raw Journal)」が独立したフォレンジック層として並走します。要約は5ストアへ、原文は生ジャーナルへ。両者はバックリンクでつながっており、要約から原文へ1ホップで戻れる構造になっています。
たとえば「先週の打ち合わせ」はEpisodicに、「自分が好むコミュニケーションスタイル」はProceduralに、「その打ち合わせがどれくらい重要だったか」はEmotionalに、というように、それぞれの性質に合った場所へ自動的に振り分けられます。
■ 「生きている記憶」とは何か:5つのダイナミクス
Cerememoryの最大の特徴は、記憶が時間とともにふるまいを変える点にあります。これが既存のメモリソリューションとの最大の違いです。ベクトルDBは記憶を保存しますが、Cerememoryは記憶を動的に生かし続ける仕様です。
忘却曲線:時間経過で少しずつ薄れていく
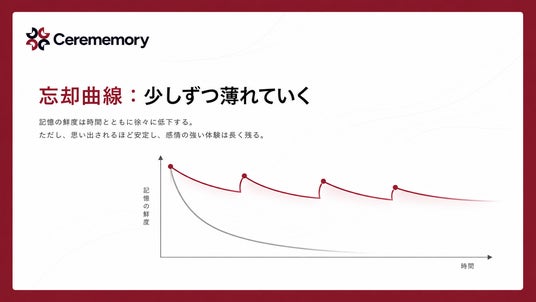
記憶の鮮度は、修正べき乗則曲線に従って徐々に低下します。「全部忘れる / 全部覚えている」の二択ではなく、現実的な劣化モデルを導入しています。何度も思い出されたものは安定し、感情的に強い体験は長く残ります。
干渉ノイズ:似た記憶は互いの細部をぼかしあう
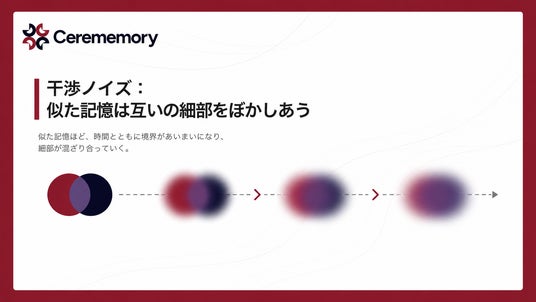
人間の記憶研究で知られる「干渉」という現象があります。似たような出来事を経験すると、時間が経つにつれて、どちらで何があったかの細部が混ざり合っていく現象です。たとえば「先月の打ち合わせ」と「先々月の打ち合わせ」が似た内容だった場合、しばらくすると区別が曖昧になっていく、あの感覚です。Cerememoryは、この干渉現象を記憶ストアの中で再現します。忠実度が下がった記憶ほどノイズが乗りやすくなり、人間の記憶に近い「不正確になりかたの自然さ」を生み出します。完璧な検索が必要な場面では、後述のPerfectモードで原文を取り出すこともできます。
拡散活性化と再固定化:思い出すたびに記憶は変わる
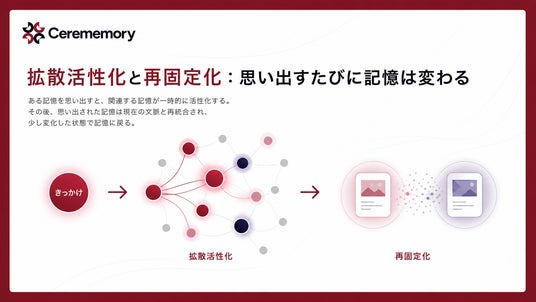
ある記憶を思い出すと、関連する記憶が一時的に活性化(拡散活性化)し、減衰していた記憶が部分的に復元されます。さらに、想起された記憶は現在のコンテキストと再統合(再固定化)されるため、思い出すたびに微妙に変化する、という人間記憶のリアリティを再現しています。人がひとつのキーワードから連想を広げていくのと同じ仕組みを、グラフ構造として実装しています。
睡眠中の夢のような記憶圧縮装置:眠っている間に記憶を整理する
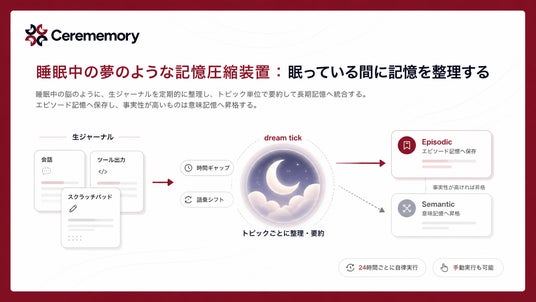
睡眠中に脳が一日の出来事を整理し、長期記憶へ統合するプロセスを、定期的なバックグラウンド処理として実装しています。生ジャーナルの原文を時間ギャップと語彙シフトでトピック単位にグルーピングし、要約してエピソード記憶へ。事実性が高ければ意味記憶へと条件付きで昇格させます。デフォルトは24時間ごとの自律実行ですが、手動での即時実行も可能です。
感情モジュレーション:心が動いた記憶ほど長く残る
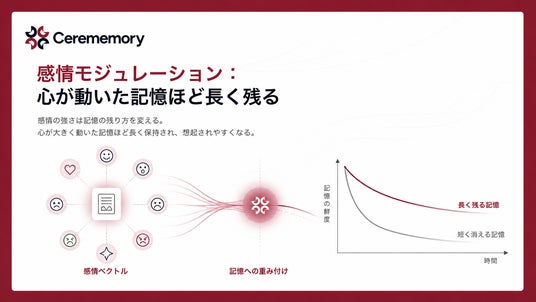
10年前の何でもない平日は思い出せないのに、はじめて怒られた日のことは鮮明に覚えている。脳の扁桃体が、感情の強さに応じて記憶の保存優先度を変えているからです。Cerememoryはこの仕組みをそのまま実装しました。
すべての記憶には、Robert Plutchikの感情モデルに基づく8次元の感情ベクトル(喜び・悲しみ、信頼・嫌悪、恐れ・怒り、驚き・期待の4組の対極ペア)が紐づきます。この感情強度が、記憶のふるまいを変えます。感情の強い記憶ほど忘却曲線の傾きがゆるやかになり、似た感情のクエリでは優先的に想起されます。さらに感情ストアは独立した「扁桃体」として、他の4ストアの記憶にも横断的に重み付けを行います。
その結果、Cerememoryを使うAIエージェントは「全部を平等に覚えている」のではなく、「ユーザーにとって心が動いた瞬間ほど、よく覚えていてくれる」というふるまいをします。
■ 技術概要
実装言語はRust、ストレージはredb、検索はTantivyとredb上の決定論的コサインインデックスを採用しています。ただしCerememoryの本質は採用技術ではなく、設計の思想にあります。注目していただきたいのは次の3点です。
メタメモリプレーン:「内容」ではなく「理由」で記憶を検索する
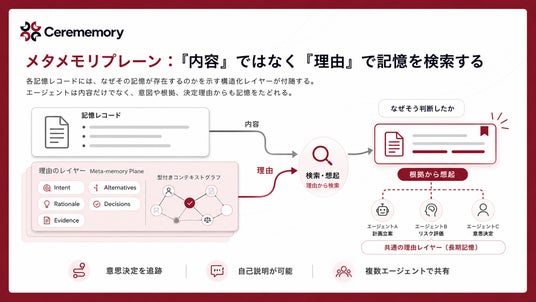
すべての記憶レコードに、「なぜこの記憶が存在するのか」を構造化して記録するプレーンが付随します。意図(intent)、根拠(rationale)、エビデンス(evidence)、代替案(alternatives)、決定(decisions)、型付きコンテキストグラフ。recall.queryはこの「なぜ」プレーンも索引するため、エージェントは「何が書かれているか」だけでなく「なぜそう判断されたか」で記憶を辿れます。
長期にわたる意思決定の追跡、エージェントによる自己説明、複数のエージェントが共通の根拠空間で議論することなどが、記憶層レベルで可能になります。
生ジャーナルとHuman/Perfectモード:人間的な不正確さと完全記録の両立
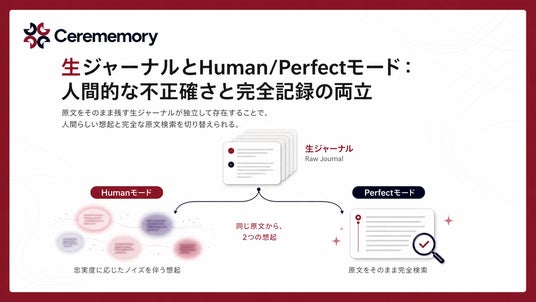
要約済みの5ストアとは別に、原文をそのまま保存する「生ジャーナル」が独立して存在します。これにより、想起時には2つのモードを使い分けられます。
- Humanモード:忠実度に応じたノイズを伴う、人間の記憶に近い現実的な想起
- Perfectモード:原文の完全な検索
Humanモードは「人間の記憶らしい曖昧さ」を提供し、Perfectモードは「監査可能な完全記録」を提供する。減衰・干渉・ノイズといった「不正確になる仕組み」と、原文へのフォレンジックアクセスを両立させているのは、生ジャーナルが独立したプレーンとして設計されているからです。単なるTTLや指数関数的減衰では再現できない領域に、構造的に踏み込んでいます。
CMPプロトコル:MCPは「APIの一種」ではなく「トランスポートの一種」である
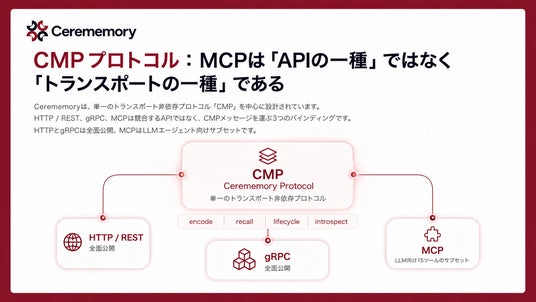
Cerememoryでは、「CMP(Cerememory Protocol)」という単一のトランスポート非依存プロトコルを中心に置き、HTTP/REST、gRPC、MCPはCMPメッセージを運ぶ3つのバインディングとして位置づけられています。HTTPとgRPCはCMPの全面(encode / recall / lifecycle / introspectの4カテゴリ)を公開、MCPはAIエージェント向けに選定されたサブセットです。どこから叩いても挙動と意味論が完全に一致するため、フロントエンド、バックエンドサービス、LLMエージェント、CLIが、まったく同じ記憶層を同じ抽象で扱えます。「AI時代のメモリ層は、APIではなくプロトコルで定義されるべき」という考えを示しています。
Claude Code、Codex、Gemini CLI、Cursor、Windsurf、など、任意のMCPクライアントから利用可能です。
■ 開発の背景と想い
AIエージェントのコンテキスト管理や記憶システムの構築は、いま世界中の開発者が取り組んでいる難題です。多くの技術者がさまざまなアプローチを提案し、日々新しい記憶アーキテクチャやコンテキスト設計が登場していますが、「これが最適解だ」と言えるベストプラクティスは、まだ確立されていません。コーレは、その潮流のなかで、日本から世界に向けて、次の時代のAIと人の関係を支える記憶システムを送り出したいと考えました。Cerememoryをオープンソースとして公開した理由はここにあります。コーレ単独で抱え込むのではなく、世界中の技術者が開発に加わり、共に磨き上げていける形でリリースすることが、この領域の進化に対する私たちなりの貢献だと考えています。
記憶という、AIと人の関係の根幹に位置するレイヤーを、誰もが参加できる共有資産として育てていきたいと考えています。
■ ライセンスと今後の展開
Cerememoryはオープンソースとして公開されています。コミュニティからのフィードバック、コントリビューションを歓迎します。
公式ドキュメント: https://co-r-e.github.io/cerememory-docs/ja
GitHubリポジトリ: https://github.com/co-r-e/cerememory
■ コーレ株式会社
コーレ株式会社は汎用的なAIプロダクトを開発する企業です。主力製品の「IrukaDark」は、日常のPC作業で何度も繰り返す、コピペ、情報のインプット、議事録、日報、タスク管理といった地味な操作など、気づかぬうちに時間を奪われて一日が溶けていくタスクを、すべて超高速に片付けます。他のAIエージェントやあらゆるアプリケーションに重ねて利用することができ、PC作業の生産性の向上に寄与します。
誰でも無料で利用できます:https://irukadark.com/ja

■ 会社概要

会社名:コーレ株式会社
英語表記:CORe Inc.
設立:2017年5月17日
所在地:東京都新宿区新宿四丁目1番6号 JR新宿ミライナタワー 18階
代表取締役CEO:奥脇 真人
取締役CTO:池田 直人
設立:2017年5月
所在地:東京都新宿区新宿4-1-6 JR新宿ミライナタワー 18階
URL:https://co-r-e.com/
企業プレスリリース詳細へ
PR TIMESトップへ